Serverless GPUs: L4, L40S, V100, and more in private preview
Today, we’re excited to share that Serverless GPUs are available for all your AI inference needs directly through the Koyeb platform!
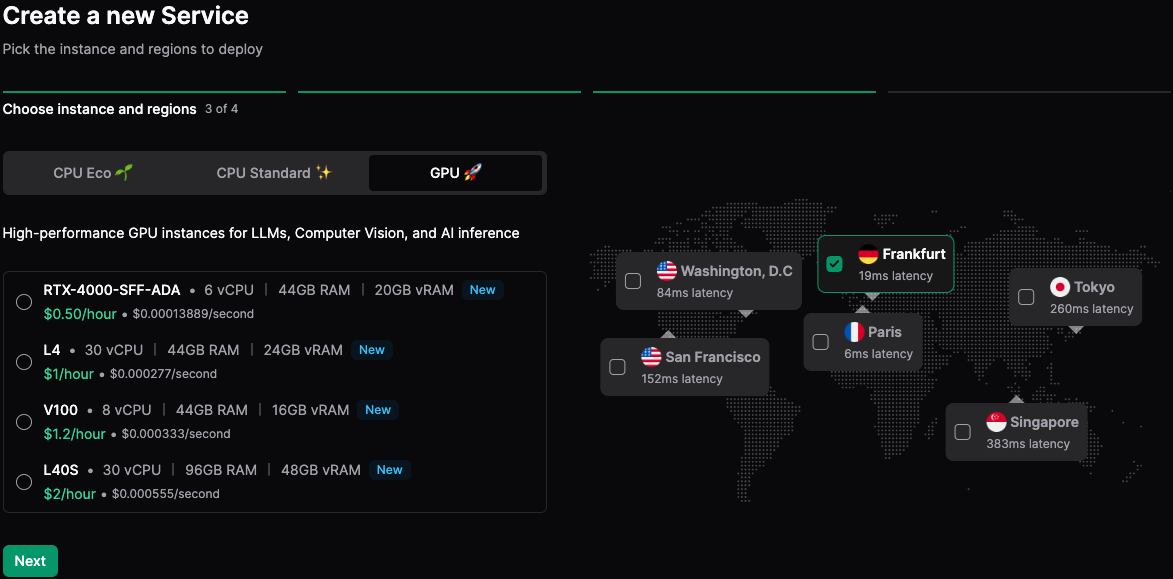
We're starting with GPU Instances designed to support AI inference workloads including both heavy generative AI models and lighter computer vision models. These GPUs provide up to 48GB of vRAM, 733 TFLOPS and 900GB/s of memory bandwidth to support large models including LLMs and text-to-image models.
We're starting with 4 Instances, starting at $0.50/hr and billed by the second:
| RTX 4000 SFF ADA | V100 | L4 | L40S | |
|---|---|---|---|---|
| GPU vRAM | 20GB | 16GB | 24GB | 48GB |
| GPU Memory Bandwidth | 280GB/s | 900GB/s | 300GB/s | 864GB/s |
| FP32 | 19.2 TFLOPS | 15.7 TFLOPS | 30.3 TFLOPS | 91.6 TFLOPS |
| FP8 | - | - | 240 TFLOPS | 733 TFLOPS |
| RAM | 44GB | 44GB | 44GB | 96GB |
| vCPU | 6 | 8 | 15 | 30 |
| On-demand price | $0.50/hr | $0.85/hr | $1/hr | $2/hr |
All these Instances have dedicated vCPUs that are equivalent to a hyperthread.
These GPUs come with the same serverless deployment experience that you know on the platform with one-click deployment of Docker containers, built-in load-balancing, and seamless horizontal autoscaling, zero downtime deployments, auto-healing, vector databases, observability, and real-time monitoring.
By the way, you can pause your GPU Instances when they're not in use. This is a great way to stretch your computing budget when you don't need to keep your GPU instances running 24/7.
To access these GPU Instances, join the preview on koyeb.com/ai. We're gradually onboarding users to ensure the best experience for everyone.
If you need GPUs in volume, let us know in your request or book a call.
Getting started with GPUs
To get started and deploy your first service backed by a GPU, you can use the Koyeb CLI or the Koyeb Dashboard.
As usual, you can deploy using pre-built containers or directly connect your GitHub repository and let Koyeb handle the build of your applications.
Here is how you can deploy a Ollama service in one CLI command:
koyeb app init ollama \
--docker ollama/ollama \
--instance-type l4 \
--regions fra \
--port 11434:http \
--route /:11434 \
--docker-command serve
That's it! In less than 60 seconds, you will have Ollama running on Koyeb using a L4 GPU.
You can then pull your favorite models and start interacting with them.
Need more? We’re just getting started
We're super excited by this release and we believe this dramatically simplifies deploying production-grade inference workloads, APIs, and endpoints thanks to the serverless capabilities of the Koyeb platform.
Our goal is to let you easily access, build, experiment, and deploy on the best accelerators from AMD, Intel, Furiosa, Qualcomm, and Nvidia using one unified platform.
If you're looking for specific configurations, GPUs, or accelerators, we'd love to hear from you. We're currently adding more GPUs and accelerators to the platform and are working closely with early users to design our offering.
Let's get in touch! Whether you require high-performance GPUs, specialized accelerators, or unique hardware configurations, we want to hear from you.
Sign up for the platform today and join the GPU serverless private preview!
Keep up with all the latest updates by joining our vibrant and friendly serverless community or follow us on X at @gokoyeb.